Property price prediction¶
In this tutorial, you will learn:
The basics in macroeconomic analysis
The ways of analyzing macroeconomic indicators
The ways of analyzing real estate market data
How to build a property price prediction model
Intro to macroeconomic analysis¶
Macroeconomic indicators in Hong Kong¶
import random
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
df.info() to print information of all columns.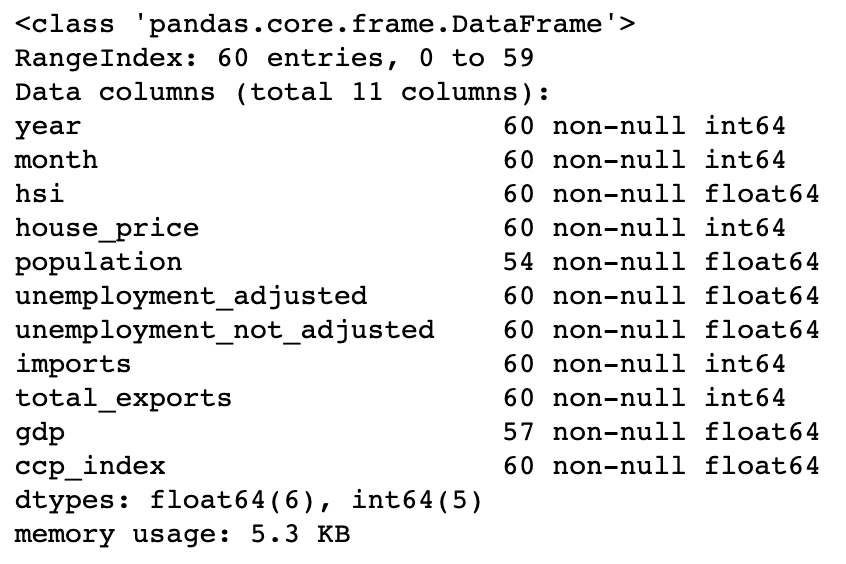
The column information of macroeconomic data.¶
Univariate analysis¶
pandas.Dataframe.describe() to examine the
distribution of the numerical features. It returns the statistical summary such as mean,
standard deviation, min, and max of a data frame.seaborn.distplot()
to visualise the results with histograms.# Statistical summary
print(df[feature_name].describe())
# Histogram
plt.figure(figsize=(8,4))
sns.distplot(df[feature_name], axlabel=feature_name);
Bivariate analysis¶
matplotlib.pyplot.scatter() and seaborn.regplot() to
visualize the relationship between two features.x = df[feature_name]
y = df['hsi']
plt.scatter(x, y)
plt.xticks(rotation=45)
fig = sns.regplot(x=feature_name, y="hsi", data=df)
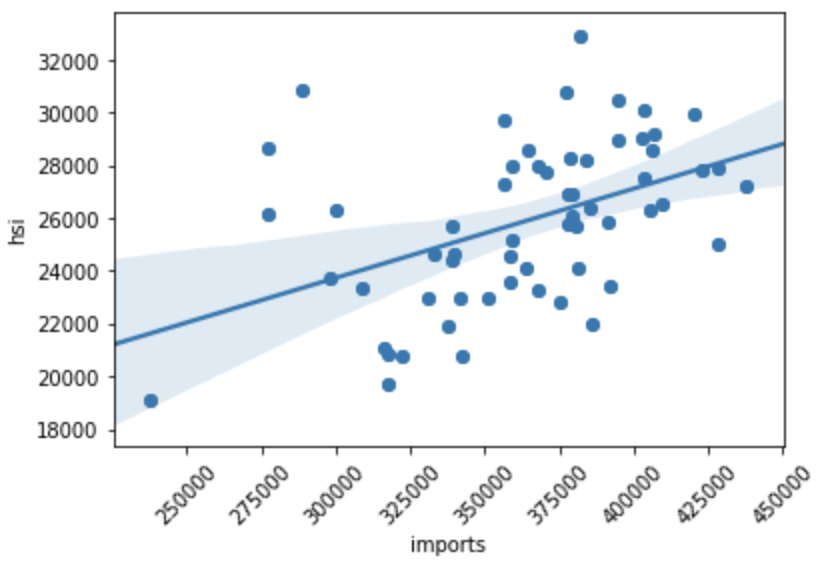
An example of a scatter plot with a regression line.¶
pandas.Dataframe.corr() and seaborn.heatmap() to compute
a pairwise correlation of features and visualize the correlation matrix.fig, ax = plt.subplots(figsize=(10,10))
cols = df.corr().sort_values('hsi', ascending=False).index
cm = np.corrcoef(df[cols].values.T)
hm = sns.heatmap(cm, annot=True, square=True, annot_kws={'size':11}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
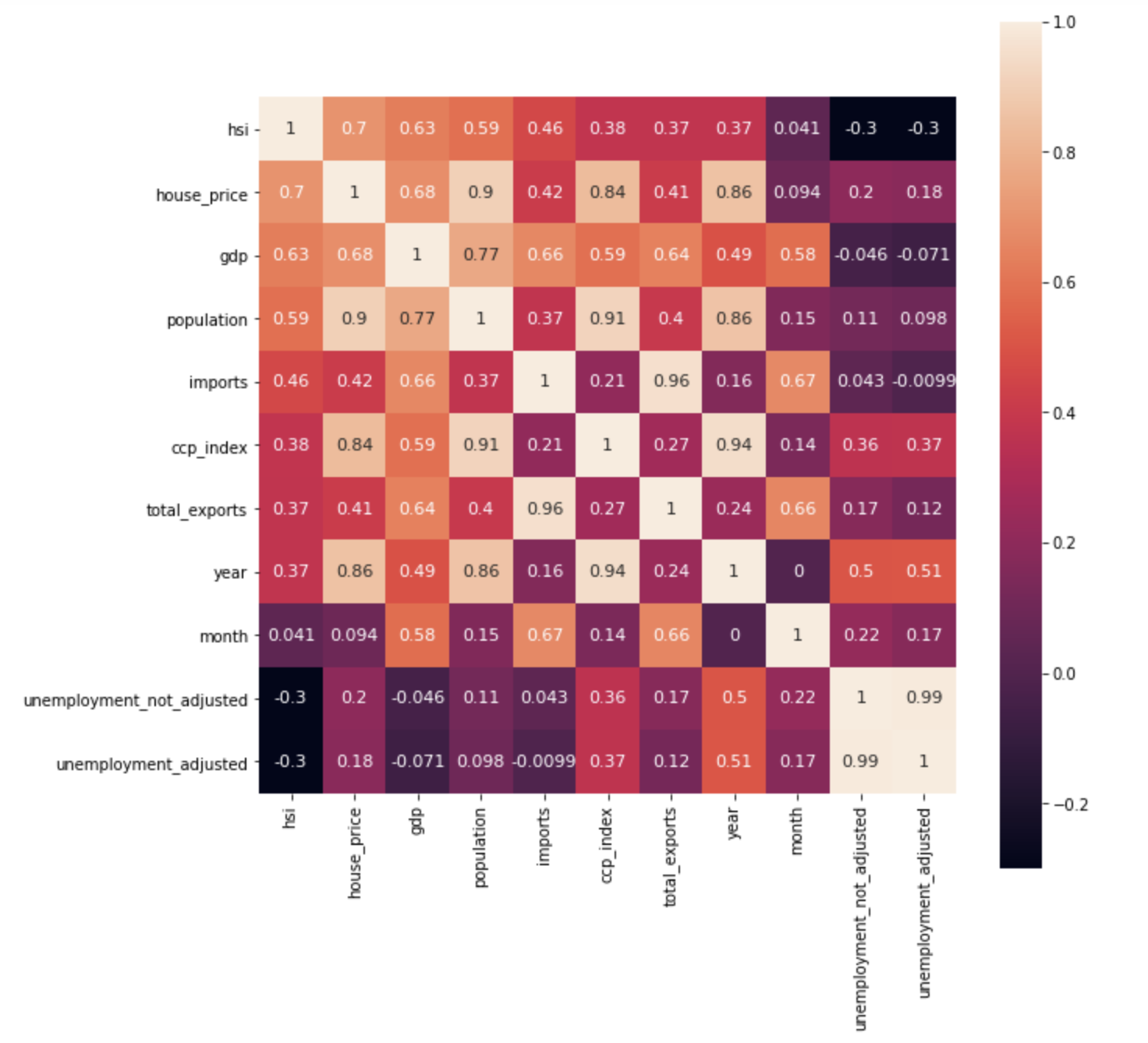
Heatmap - macroeconomic indicators of Hong Kong.¶
The Hong Kong real estate market¶
Data pre-processing¶
1. Derive some useful features from existing features.
# Add new features
df['month'] = pd.to_datetime(df['RegDate']).dt.month
df['year'] = pd.to_datetime(df['RegDate']).dt.year
2. Drop unmeaningful features and features with too many missing values
# Drop unnecessary columns
df = df.drop([feature_name], axis=1)
3. Handle missing values by replacing NAN with a mean value of a feature
# Handling missinig values
# Fill with mean
feature_name_mean = df[feature_name].mean()
df[feature_name] = df[feature_name].fillna(feature_name_mean)
Label encode categorical features
le = LabelEncoder()
le.fit(list(processed_df[feature_name].values))
processed_df[feature_name] = le.transform(list(processed_df[feature_name].values))
Economic indicator analysis¶
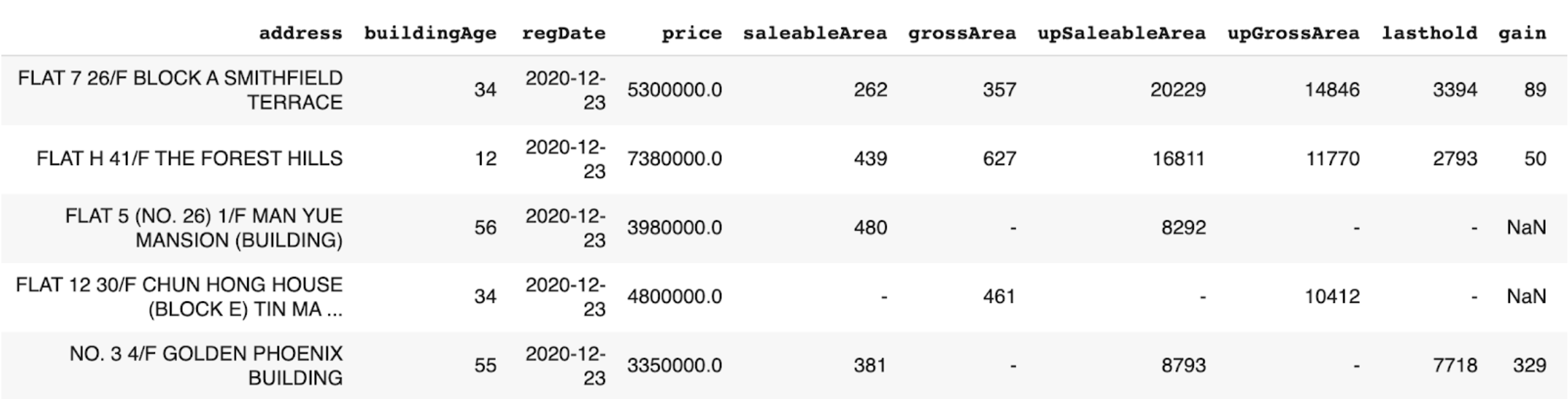
The data structure of transaction record (Centaline Property).¶
# calculate the monthly average house price
df = df.groupby(['year','month'],as_index=False).mean()
df = df.rename(columns={'UnitPricePerSaleableArea': 'AveragePricePerSaleableArea'})
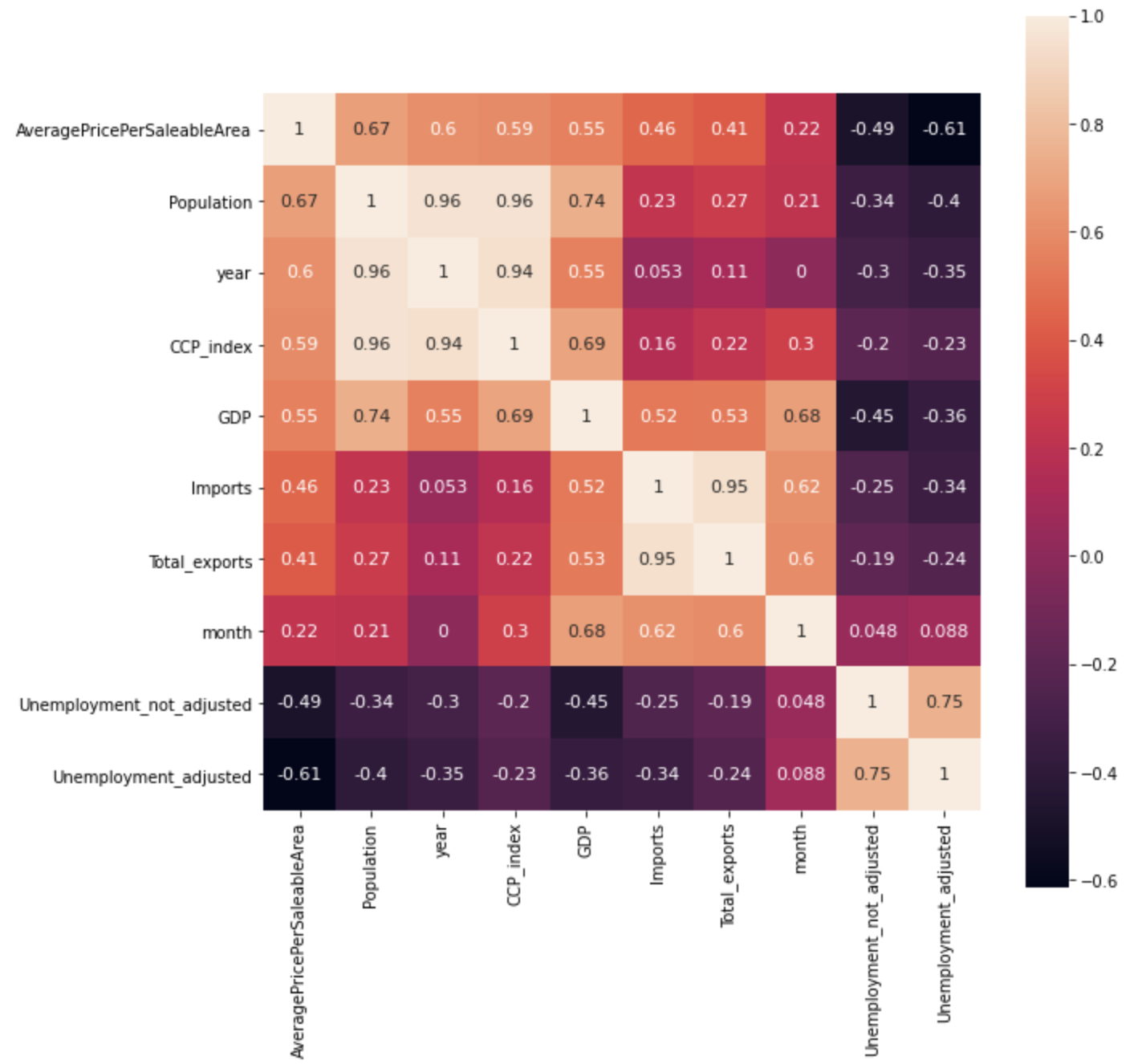
Heatmap - economic indicators analysis.¶
Transaction record analysis¶
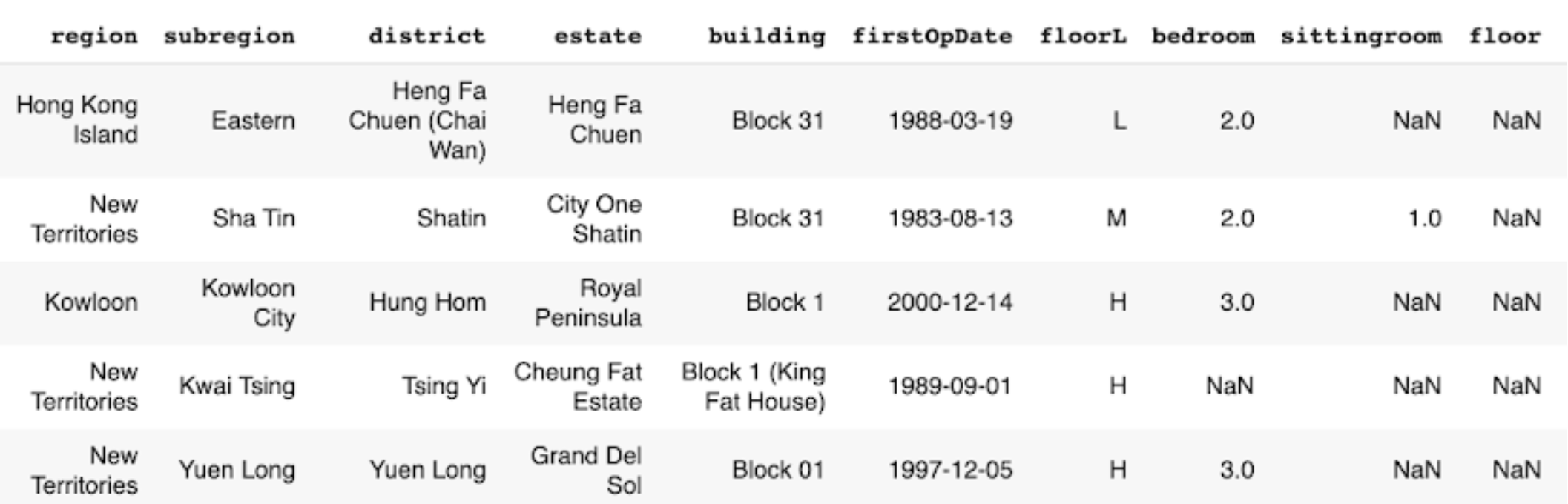
The data structure of transaction record (Midland Realty) - Part 1.¶
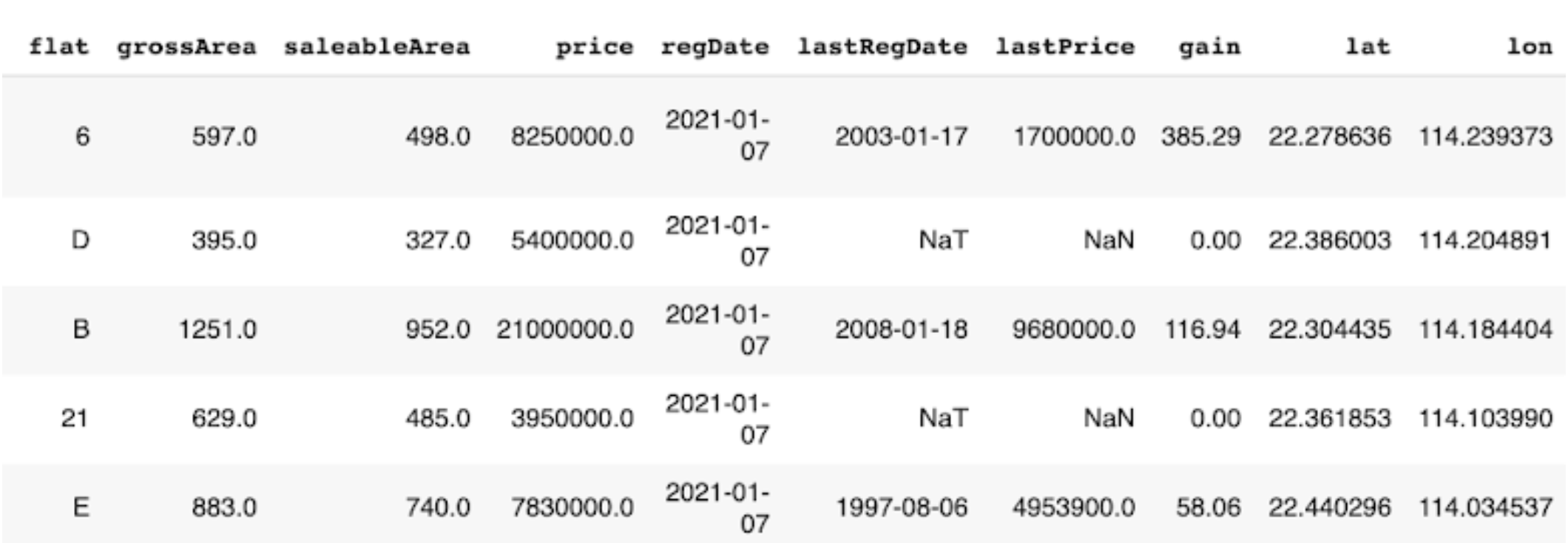
The data structure of transaction record (Midland Realty) - Part 2.¶
# Distribution
print(df['price'].describe())
# Skewness and kurtosis
print("Skewness: ", df['price'].skew())
print("Kurtosis: ", df['price'].kurt())
#output:
count 1.664090e+05
mean 9.133268e+06
std 1.310856e+07
min 5.500000e+05
25% 5.200000e+06
50% 6.830000e+06
75% 9.500000e+06
max 1.399000e+09
Name: price, dtype: float64
Skewness: 26.927207752922435
Kurtosis: 1526.4066673335874
# Calculate mean and standard deviation
data_mean, data_std = np.mean(df[feature_name]), np.std(df[feature_name])
# Calculate upper boundary
upper = data_mean + data_std * 3
# Remove outliers
df = df[df[feature_name] < upper]
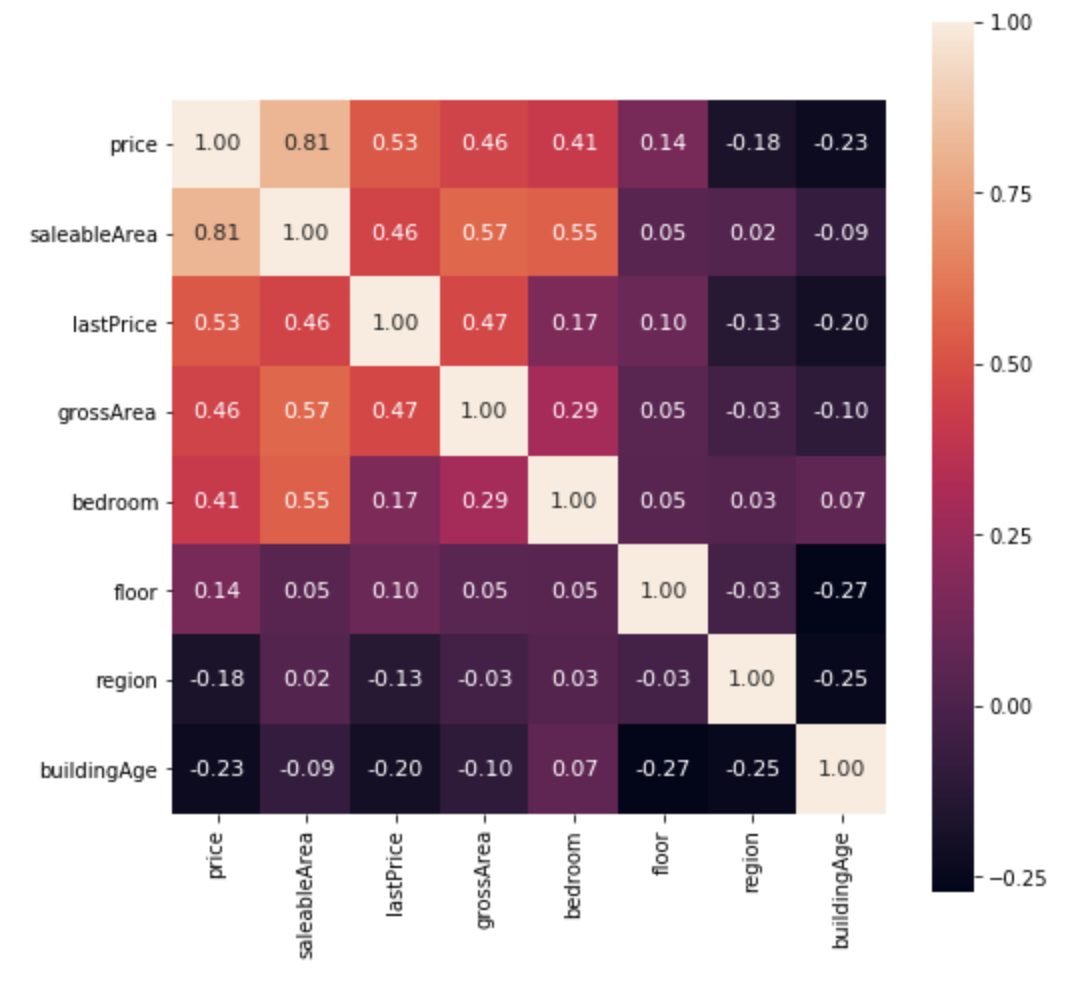
Heatmap - transaction data analysis.¶
code/macroeconomic-analysis/ in the repository.Property price prediction with machine learning¶
Train-test split¶
sklearn.model_selection.train_test_split() to split the data with the ratio
of 8:2. The input variables are the top 7 features selected from the analysis, and
the output feature is the house price.feat_col = [ c for c in df.columns if c not in ['price'] ]
x_df, y_df = df[feat_col], df['price']
x_train, x_test, y_train, y_test = train_test_split(x_df, y_df, test_size=0.2, random_state=RAND_SEED)
Log transformation¶
y_train using log function to normalise the highly
skewed price data. In this way, the dynamic range of Hong Kong’s property price can be reduced.log_y_train= np.log1p(y_train)
Training the model¶
XGBoost
Lasso
Random Forest
Linear Regression
x_train and y_train, and use the
models to make the predictions.import xgboost as xgb
# XGBoost
model_xgb = xgb.XGBRegressor(objective ='reg:squarederror',
learning_rate = 0.1, max_depth = 5, alpha = 10,
random_state=RAND_SEED, n_estimators = 1000)
model_xgb.fit(x_train, log_y_train)
xgb_train_pred = np.expm1(model_xgb.predict(x_train))
xgb_test_pred = np.expm1(model_xgb.predict(x_test))
Evaluate accuracy¶
from sklearn.metrics import mean_squared_log_error
def rmsle(y, y_pred):
return np.sqrt(mean_squared_log_error(y, y_pred))
#output:
XGBoost RMSLE(train): 0.1626671056150446
XGBoost RMSLE(test): 0.16849945199484243
plt.figure(figsize=(5,5))
plt.scatter(y_test,xgb_test_pred)
plt.xlabel('Actual Y')
plt.ylabel('Predicted Y')
plt.show()
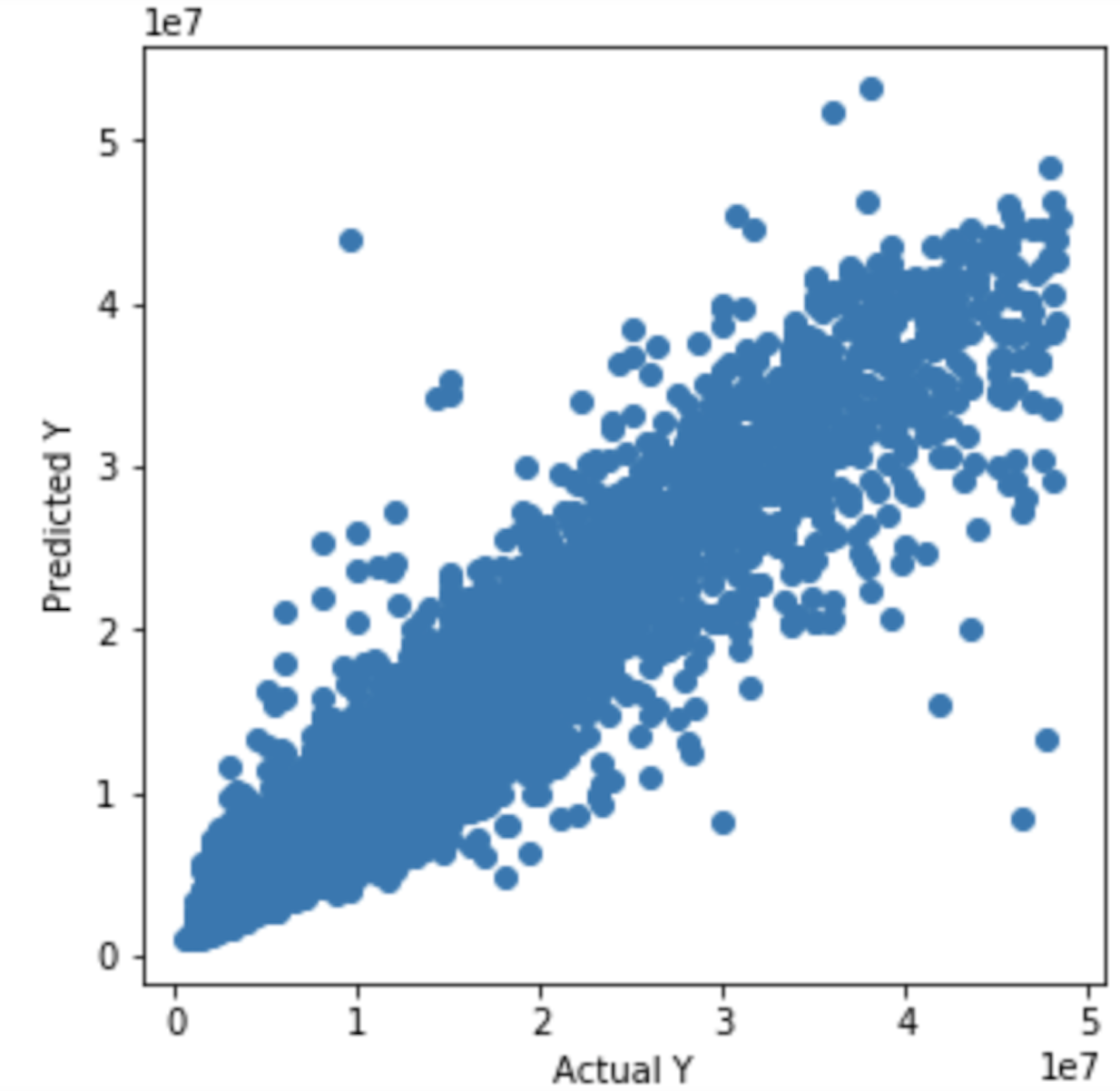
The graph of actual and predicted house price for XGBoost.¶
Attention